
はじめに
Excelは表計算ソフトとして広く使われていますが、実は統計解析にも非常に便利な機能を備えています。あまり知られていませんが
・基本統計量の計算
・分布の確率計算
・仮説検定
など、統計分析に役立つ関数が数多く標準搭載されているんです。
しかし実務では「平均」や「標準偏差」などの基本関数しか使われていないケースも少なくありません。(勿体ない・・・)
実際にはExcelを使うことで「正規分布の確率計算」「T検定/F検定」「相関係数」など、統計解析に役立つ指標や検定を関数を使って20秒で計算することができます。
この記事では、統計解析でよく使われるExcel関数について、「どんなものがあるか?」「具体的な使い方」に着目してわかりやすく解説します!
基本統計量を求める関数
まずはデータの特徴を把握するための基本統計量です。
主なものとして以下があります。
| 内容 | Excel関数 |
|---|---|
| 平均 | AVERAGE |
| 中央値 | MEDIAN |
| 最頻値 | MODE.SNGL |
| 分散 | VAR.S |
| 標準偏差 | STDEV.S |
次項以降で、それぞれの関数を用いた計算方法について詳しく説明していきます。
平均値(AVERAGE)
平均は「データの中心」を表す代表値です。
Excelでは以下の関数で求めることができます
Excel関数
=AVERAGE(A1:A10)
例;売上データから求める
以下に売上データが5つあります
120, 150, 130, 170, 140
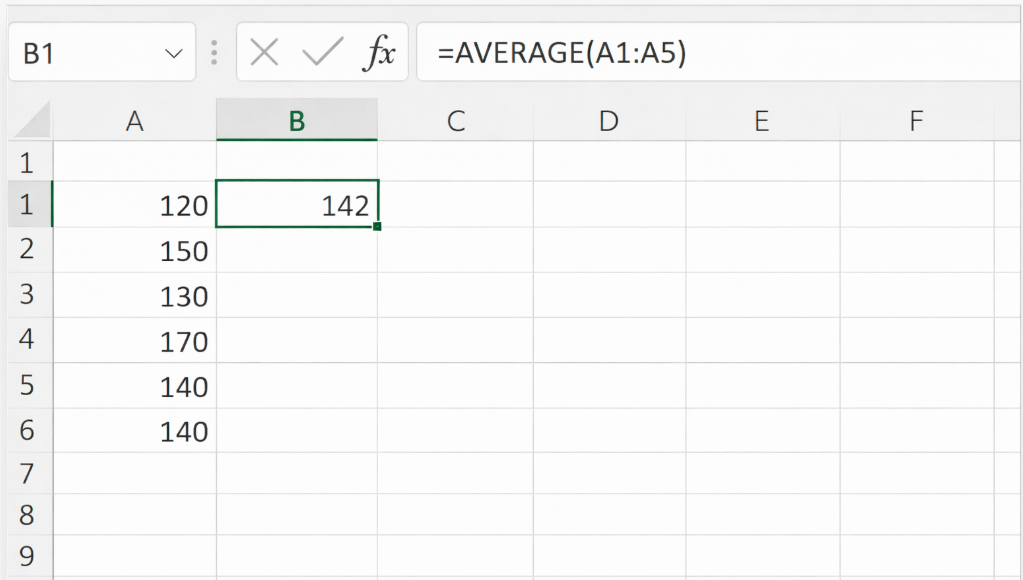
平均売上を求める場合、以下の関数で求めることができます
(データがA1:A5にある前提)
=AVERAGE(A1:A5)
結果、平均値は以下になります(実際に求めてみて、値が一致するか確認しましょう)
142
中央値(MEDIAN)
中央値は、データを小さい順に並べたとき中央に位置する値です。
Excelでは以下の関数で求めることができます
Excel関数
= MEDIAN(A1:A10)
例;年収データから求める
以下に都市部サラリーマンの年収のデータが7つあります
300, 459, 512, 800, 812, 900, 2134
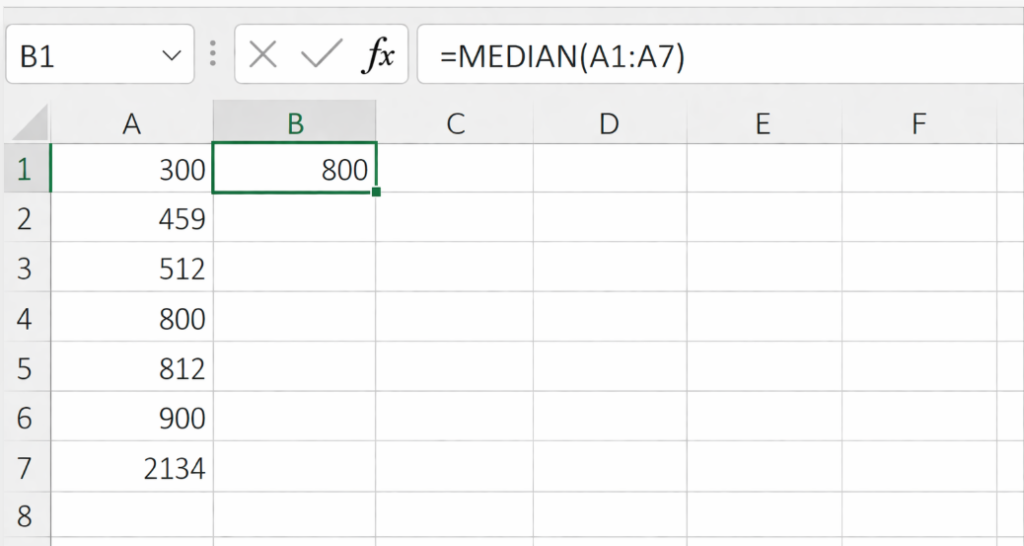
年収中央値を求める場合、以下の関数で求めることができます
(データがA1:A7にある前提)
= MEDIAN(A1:A7)
結果、平均値は以下になります(実際に求めてみて、値が一致するか確認しましょう)
800
ここで着目したいのは、中央値の場合「2134」といった外れ値が存在しても計算結果に影響を与えていないという点です。
このように、中央値は「外れ値」や「分布のゆがみ」に対して頑健性が高い点にも注目したいです。
活用例:
・年収データ
・不動産価格
など、外れ値の影響を受けやすいデータに有効です。
工学の分野でも外れ値(測定ミス・特定のLotの特異的な値」があることも多いので
その様な値が含まれる場合は有効な指標です。
最頻値(MODE.SNGL)
最頻値はデータの中で最も多く出現する値を示します。
Excelでは以下の関数で求めることができます。
Excel関数
=MODE.SNGL(A1:A10)
例;アンケート調査
以下に地方にて実施した「子供の数」のアンケート結果をがあります
0, 1, 0, 1, 3, 4, 2, 1, 1, 2, 3, 4, 1, 0
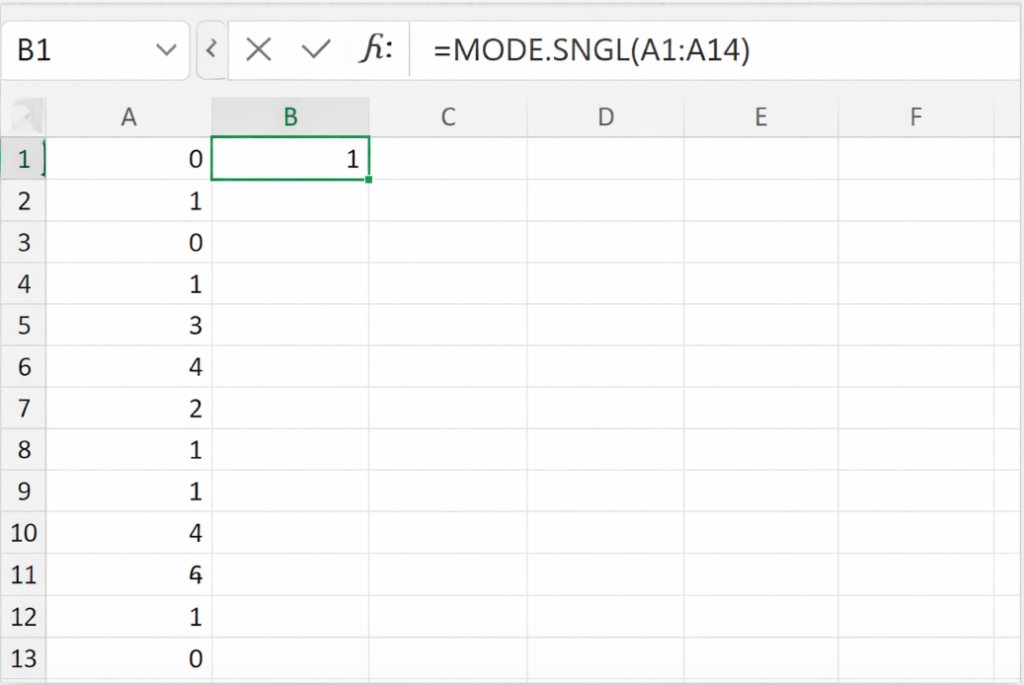
ここから最頻値を求める場合、以下の関数で求めることができます
(データがA1:A14にある前提)
=MODE.SNGL(A1:A14)
結果、得られた最頻値は以下になります
(実際に求めてみて、値が一致するか確認しましょう)
1(人)
活用例;
・アンケート調査の分析
・最も多いサイズ
・人気商品のあたり付け
上記の様はカテゴリカルデータの分析で用いられることが多いですが
工学の分野での活用は多くありません。
ばらつきを求める関数
データ分析では、平均だけでなくばらつきも重要です。
以下にバラつきの計算で用いられる指標および関数の一覧を掲載します。
| 内容 | Excel関数 |
|---|---|
| 分散 | VAR.S |
| 標準偏差 | STDEV.S |
分散(VAR.S)
分散はデータのばらつきの大きさを表す指標です。
Excelでは以下の関数で求めることができます。
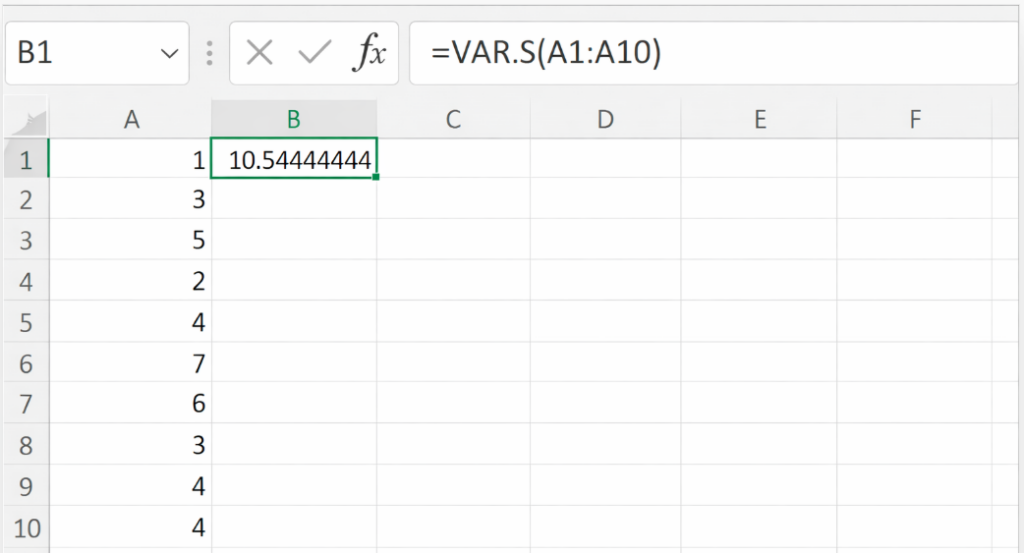
(データがA1:A10にある前提)
Excel関数
=VAR.S(A1:A10)
注意;関数の使い分けについて
Excel関数には
・VAR.S
・VAR.P
の2種類があります。
ちなみに”S”はsample(サンプル)の意、”P”はpopulation(ポピュレーション)の意です。
| 関数 | 意味 |
|---|---|
| VAR.S | 標本分散 |
| VAR.P | 母分散 |
通常のデータ分析では VAR.S を使うことが多いです。
なぜなら、工学の分野で母集団(ポピュレーション)全体からデータを得られることは想定されないからです。
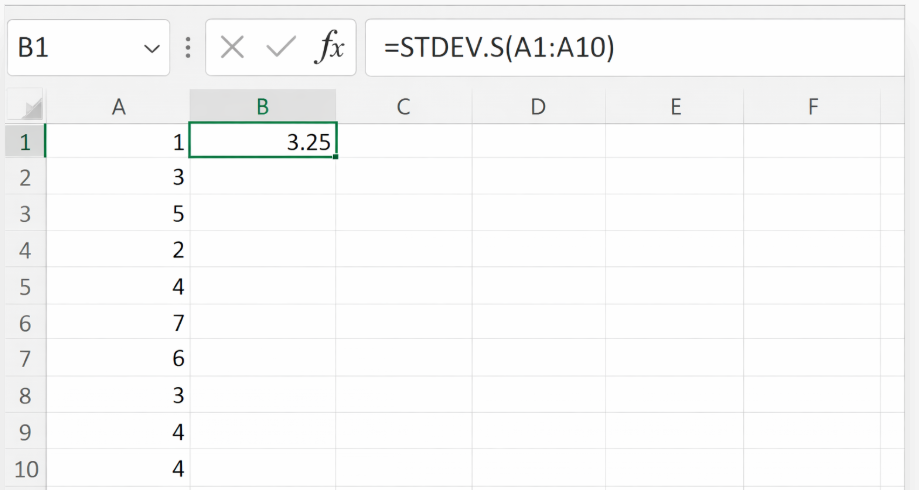
標準偏差(STDEV.S)
標準偏差は、分散の平方根であり、データのばらつきを直感的に表します。
平方根を取る理由は、分散の計算過程で2乗してしまった計算結果の次元を元に戻すためです。
Excelでは以下の関数で求めることができます。
(データがA1:A10にある前提)
Excel関数
=STDEV.S(A1:A10)
これも、分散同様に
・STDEV.S
・STDEV.P
があります。こちらも”S”と”P”の考え方は同様で、“S”を用いるのが無難です。
正規分布の確率計算
Excelでは正規分布に基づく確率計算もできます。
以下が主に用いられる関数です。
| 内容 | Excel関数 |
|---|---|
| 正規分布の確率 | NORM.DIST |
| 正規分布の逆関数 | NORM.INV |
正規分布確率(NORM.DIST)
この関数では、一言で表すと「母集団について正規分布を仮定したとき、ある値が分布の上位〇%か」を求めることができます。
わかりやすい例を挙げると、
・あるテストで60点の人は、全受験者の上位〇%なのか?
・出荷製品全体の中で、”寸法50mm”だった製品は分布の〇%なのか?(極端に高い値か?)
といった具合です。
例えば、「平均=50」「標準偏差10」の正規分布を仮定した際、
X ≤ 60
の確率を求める場合、以下の関数で求めることができます
Excel関数
=NORM.DIST(60,50,10,TRUE)
=0.841
となります。
このように、正規分布をもとにした確率計算も関数を用いて容易に行うことができます。
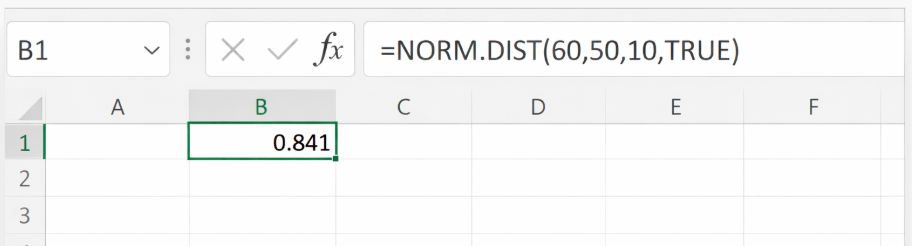
つまり「60点以下の人は全体の84.1%を占める」と解釈できます
※表現としては、1-0.841=0.159とすると「60点の人は上位15.9%」と理解できます。
この方がわかりやすいです
※この時、関数の末尾の項に出てくる”TRUE”は「累積確率」を意味します。
正規分布の逆関数(NORM.INV)
この関数では、一言で表すと「母集団について正規分布を仮定したときの、上位〇%の値」を求めることができます。
わかりやすい例を挙げると、
・テストの全受験者の上位5%の人の点数は〇点?
・出荷製品全体の中で、寸法の大きさが上位10%の製品は〇mm?
といった具合です。
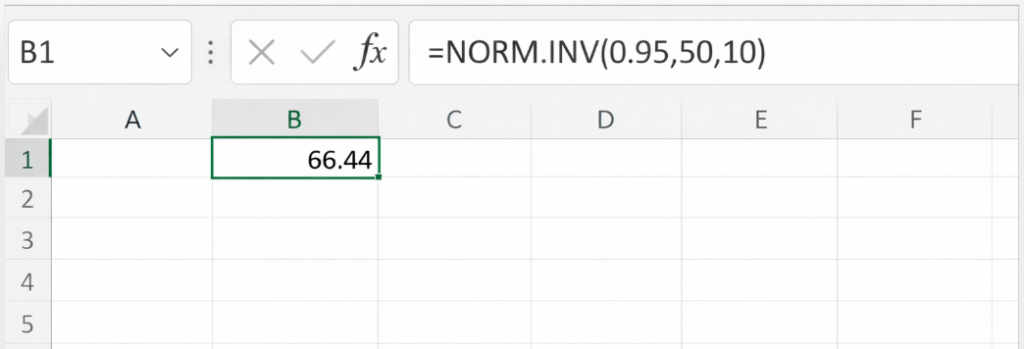
例えば、「平均50、標準偏差10の正規分布」を仮定するテストの中で「上位5%」の点数の値を求める場合を求めると
=NORM.INV(0.95,50,10)
=66.44
となります。
この場合、点数=66.44の人が上位5%に位置することがわかります
※求めたい値が「上位5%」の場合、関数の先頭の項には1-0.05=0.95を入力してください。
仮説検定に使う関数(T検定/F検定)
Excelでは関数を用いて統計的仮説検定も行うことができます。
仮説検定とは、簡単に言うと
「2つのデータの差は偶然なのか、それとも意味のある差なのか?」
を統計的に判断する手法です。
Excelの検定関数は、結果として「 p値(p-value)」を返します。
p値とは、わかりやすく説明すると「今回得られた”差”が起きる確率」を意味します。
一般的な統計解析では
| p値 | 判断 |
|---|---|
| p < 0.05 | 有意差あり |
| p ≥ 0.05 | 有意差なし |
という基準がよく用いられます。
つまり、関数を用いて統計的仮設検定を行った際に
p値 < 0.05
の結果が得られた場合統計的に有意な差があると判断します。
Excelでは代表的な仮説検定として
・T検定 (2群間の平均値の差)
・F検定 (2群間の分散の差)
を関数で計算することができます。
以降にてそれぞれの具体的なやり方・結果の解釈について紹介します
T検定(T.TEST)
T検定は「2つのデータの平均値に統計的な差があるか」を検定する方法です。
例えば次のようなケースで使われます。
・改善前と改善後の工程データ
・新製品と旧製品の性能
・2つの設備の加工精度
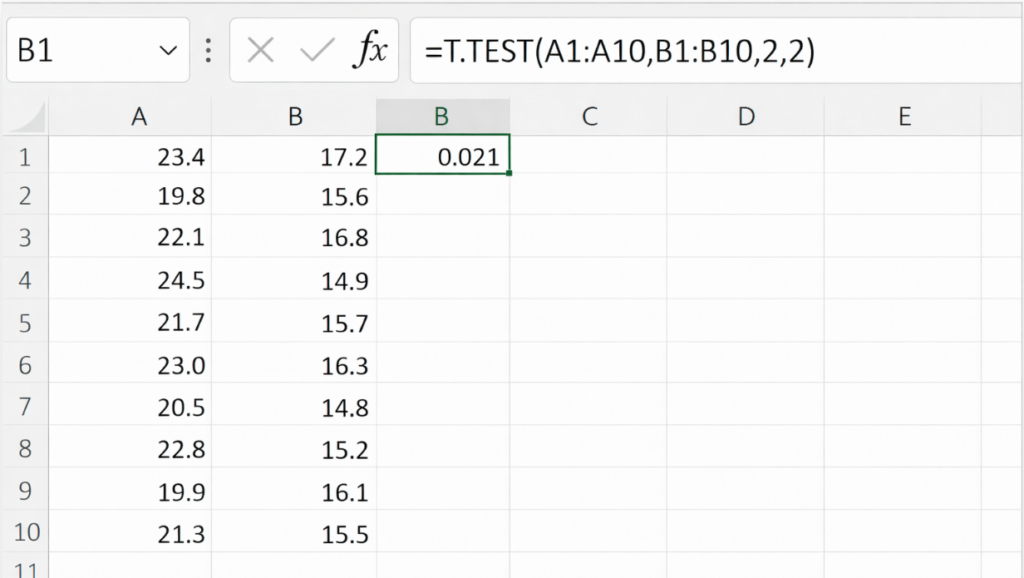
Excelでは以下の関数で計算できます。
Excel関数
=T.TEST(A1:A10,B1:B10,2,2)
引数の意味
T検定は因数が複雑なため、以下に整理したものを掲載します。
| 引数 | 意味 |
|---|---|
| A1:A10 | データ1 (1群) |
| B1:B10 | データ2 (2群) |
| 2 | 両側検定 ※1の場合は片側検定 |
| 2 | 等分散 ※1の場合は非等分散 |
結果の解釈
関数の結果は p値 です。
計算の事例を以下に記載します。
=T.TEST(A1:A10,B1:B10,2,2)
=0.021
この場合、得られたp値=0.021 < 0.05なので、2つの平均には統計的に有意な差があると判断できます。

Excel分析ツールを用いたT検定の手順・結果の解釈をわかりやすく解説!
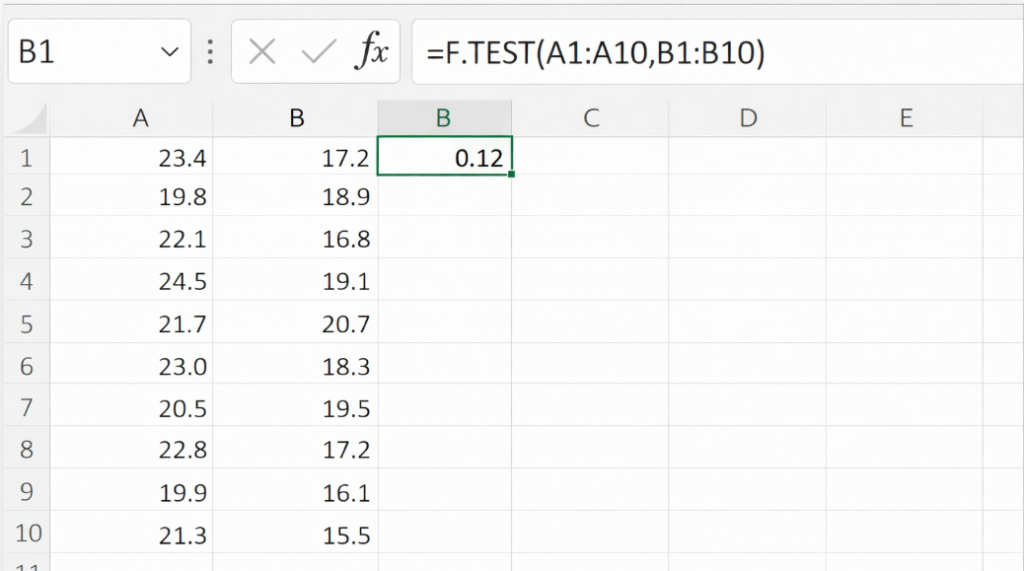
F検定(F.TEST)
F検定は「2つのデータの分散(ばらつき)が等しいか」を検定する手法です。
例えば以下を比較するときに使います。
・設備Aと設備Bのばらつき
・新工程と旧工程の安定性
Excelでは以下の関数で求めることができます。
Excel関数
=F.TEST(A1:A10,B1:B10)
引数の意味
以下に整理したものを掲載します。
| 引数 | 意味 |
|---|---|
| A1:A10 | データ1 (1群) |
| B1:B10 | データ2 (2群) |
F検定は、引数に「検定の指定」と「検定の種類」がありません。
結果はすべて両側検定の結果として出力されます。
結果の解釈
この関数も p値 を返します。
計算の事例を以下に記載します。
※1群のデータがA1:A10、2群のデータがB1:B10にある想定です
=F.TEST(A1:A10,B1:B10)
=0.12
この場合p値=0.12 > 0.05のため、「2つの分散に有意な差はない」と判断します。

Excel分析ツールを用いたF検定の手順・結果の解釈をわかりやすく解説!
※補足:実務では
・F検定 → 等分散か確認
・T検定 → 平均差を確認
という流れで使うこともあります。
T検定には引数の中に「等分散」「非等分散」が存在し、それぞれでP値の結果が変わることもありますので、先にF検定を実施し、等分散かを確認したのちにT検定を行うのがより間違いの少ない流れです。
その他の便利な統計関数
Excelには他にも便利な統計関数があります。
以下に実務で活用できるExcel関数の一覧を掲載しています。
具体的な使い方についてもいくつかピックアップして紹介します。
| 内容 | Excel関数 |
|---|---|
| 相関係数 | CORREL |
| 共分散 | COVARIANCE.S |
| パーセンタイル | PERCENTILE |
| 四分位数 | QUARTILE |
| 回帰分析 | LINEST |
相関係数(CORREL)
相関係数は「2つのデータの関連性の強さ」を表す指標です。
Excelでは CORREL関数 を使って計算できます。
Excel関数例:
以下の関数で求めることができます
・A1:A10 → 配列1のデータ
・B1:B10 → 配列2のデータ
を示します。
=CORREL(A1:A10,B1:B10)
相関係数の値の範囲
相関係数は「-1 ~ +1」の範囲の値を取ります。
結果の解釈については、参考として値の意味合を以下の表で紹介します。
| 相関係数 | 意味 |
|---|---|
| +1 | 完全な正の相関 |
| 0 | 相関なし |
| -1 | 完全な負の相関 |
相関のイメージ
| 相関 | 内容 |
|---|---|
| 正の相関 | Aが増えるとBも増える |
| 負の相関 | Aが増えるとBは減る |
| 相関なし | 関係なし |
よくされる使用例
ここでは相関係数の値について感触を掴んでいただくため、簡単な事例で紹介します。
例えば、下の事例には以下の様な関係があります
・「気温⇔アイスクリーム売上」→正の相関
・「気温⇔暖房使用料」→負の相関
ExcelのCORREL関数を使うことで、
このような関係性の強さを簡単に数値化することができます。

データの関連性を見る統計指標!相関係数についてわかりやすく解説!
パーセンタイル(PERCENTILE)
パーセンタイルとは「データを小さい順に並べたときの位置」を示す指標です。
例えば、パーセンタイルの値として以下の様な意味合いを持ちます
| パーセンタイル | 意味 |
|---|---|
| 50% | 中央値 |
| 90% | 上位10%の境界 |
| 95% | 上位5%の境界 |
Excel関数
Excelでは PERCENTILE関数 を使って求めることができます。
=PERCENTILE(A1:A100,0.9)
引数の意味
| 引数 | 意味 |
|---|---|
| A1:A100 | データ範囲 |
| 0.9 | 90パーセンタイル |
例:テストの上位10%に該当する点数は?
A1:A100のセルに100人のテスト結果がある場合
=PERCENTILE(A1:A100,0.9)
とすると上位10%の境界の点数を求めることができます。
活用例
パーセンタイルは実務でもよく使われます。
・テストの上位10%
・製品寿命の90%点
・品質保証の信頼水準
品質工学の分野では寿命試験や信頼性評価などでよく利用される指標です。
Excel統計関数まとめ
今回は実務で活用できるExcel関数について紹介しました。
主要なExcel統計関数をまとめると次の通りです。
| 分類 | 関数 |
|---|---|
| 代表値 | AVERAGE / MEDIAN / MODE |
| ばらつき | VAR / STDEV |
| 分布 | NORM.DIST |
| 仮説検定 | T.TEST / F.TEST |
| 関係性 | CORREL |
| 分位点 | PERCENTILE / QUARTILE |
Excelを使うことで、専門的な統計ソフトがなくても多くの統計解析を行うことができます。
処理もすぐに終わるので、ぜひ実務で活用してみてください
まとめ
この記事では、Excelで使える統計関数について解説しました。
Excelには「平均」「分散」「標準偏差」「仮設検定」など、統計解析に役立つ関数が数多く用意されています。
これらを活用することで
・データ分析
・品質管理のための統計量の計算
・工程改善
など、さまざまな場面でデータを有効に活用することができます。
Excelは最も身近な統計ツールの一つです。
基本的な統計関数を理解し、データ分析に活用してみてください!