
はじめに
統計解析というと、平均、分散、相関係数、回帰分析など、
「集めたデータをどう分析するか」に注目しがちです。
もちろん分析手法はとても重要です。
しかし、統計で本当に大切なのは、分析に入る前の段階でもあります。
それが、どのような母集団を想定し、そこからどのようにデータを取得するかという考え方です。
たとえば、どれだけ高度な解析手法を使ったとしても、集めたデータが母集団を適切に反映していなければ、得られた結果の信頼性は大きく下がってしまいます。
つまり、統計解析では
解析手法の前に、どの母集団を対象として、どうデータを取るかを考えることが重要
なのです。(本当に・・・大事です)
今回は、統計の基礎として非常に重要なデータの取得方法(標本抽出法)について、
代表的な手法を整理しながら丁寧に解説します。
※この内容は、QC検定/統計検定ともに頻出です!
まず大切なのは「母集団」を考えること
データを集める前に、まず考えなければならないのが母集団です。
母集団とは、本来知りたい対象全体のことです。
たとえば、
などが母集団になります。
しかし、現実には母集団全体を毎回調べるのは難しいことが多いです。
そこで、母集団の一部を取り出して調べます。
この取り出した一部を標本といいます。
統計解析では、この標本をもとに母集団の特徴を推定します。
だからこそ、
・どんな母集団を想定しているのか
・その母集団を代表するように標本が取れているのか
がとても重要になります。
標本抽出とは何か?
標本抽出とは、母集団から一部のデータを取り出す方法のことです。
この抽出方法が適切でないと、
・偏った人だけが選ばれる
・特定の条件のデータばかり集まる
・母集団全体の傾向を正しく反映できな
といった問題が起こります。
つまり、統計解析の質は、どんな分析をしたかだけでなく、どんな取り方をしたかにも大きく左右されるということです。
全数調査と標本調査
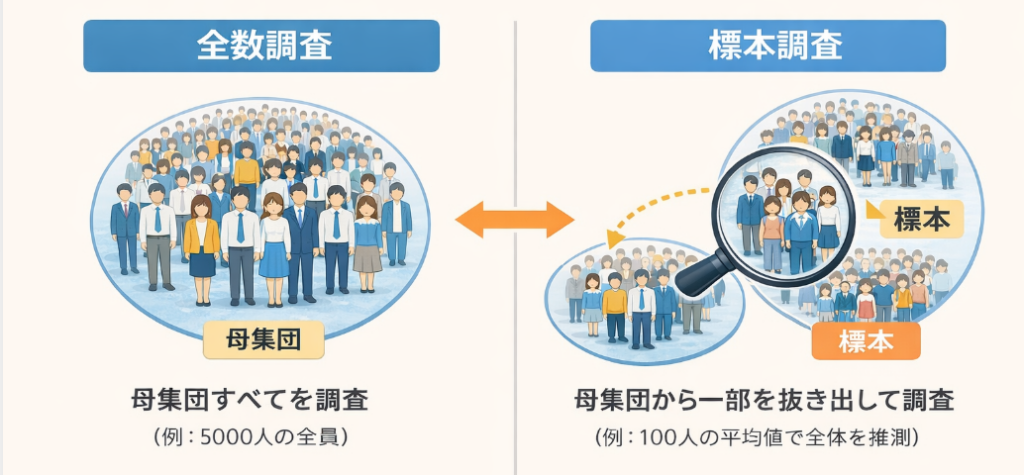
データの取得方法を考えるとき、まず整理しておきたいのが全数調査と標本調査の違いです。
データの取得方法については、突き詰めるとこの二つに分かれます。
以下にそれぞれの意味合いについて解説します
全数調査
母集団全体を調べる調査のことを指します。
たとえば、
・国勢調査
・全製品の調査
・全社員へのアンケート
などが該当します。
母集団全体を調べるため理想的ではありますが、時間、費用、手間の面で負担が大きくなることがあります。
標本調査
母集団の一部だけを取り出して調べる方法です。
多くの統計解析ではこちらが使われます。
ただし、標本調査では取り方次第で結果が大きく変わるため、抽出法の理解が重要になります。
(次項以降ではこの”標本調査”について、それぞれ詳しく解説しています)
無作為抽出とは?
統計で基本となる考え方の1つが無作為抽出です。
無作為抽出とは、母集団の各要素ができるだけ公平に選ばれる chance を持つように抽出する方法です。
ここで大事なのは、無作為 = いい加減ではないという点です。
統計でいう無作為とは、感覚的に適当に選ぶことではなく、
選ばれ方に偏りが入りにくいようにすることを意味します。
無作為抽出ができていないと、標本が母集団を代表しにくくなり、推定や検定の前提が崩れやすくなります。
代表的な標本抽出法
ここからは、統計の基礎や統計検定でよく扱われる代表的な抽出法を整理していきます。
1. 単純無作為抽出法
単純無作為抽出法は、母集団の中からすべての要素が等しい確率で選ばれるように抽出する方法です。
もっとも基本的な抽出法で、くじ引きのようなイメージに近い方法です。
たとえば、1000人の名簿があり、その中から乱数表や乱数生成を使って100人を選ぶような方法です。
特徴
・考え方がシンプル
・理論的に扱いやすい
・偏りを抑えやすい
注意点
・母集団全体の名簿が必要になることが多い
・実務では手間がかかる場合がある
統計の理論では基本形としてよく出てきますが、実際にすべてのサンプルを等しい確率で取得することは難しいです。そのため現場では別の抽出法が使われることも少なくありません。
2. 層化抽出法
層化抽出法は、母集団をいくつかの層に分けたうえで、各層から抽出する方法です。
たとえば、以下のような層別が良く行われます
・男女で分ける
・年代別に分ける
・地域別に分ける
・部署別に分ける
といった形で、あらかじめ母集団を性質の似たグループに分け、その中から標本を取ります。
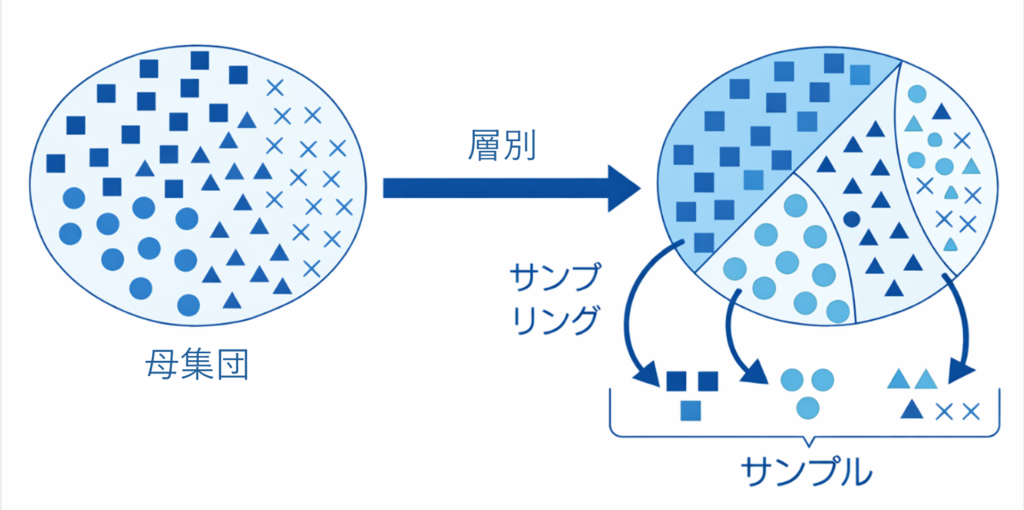
なぜ層化するのか?
母集団の中に異なる特徴を持つ集団が混ざっていると、単純無作為抽出では偏りが出ることがあります。
たとえば、年代ごとに意見が大きく違う調査で、たまたま若年層ばかり多く抽出されると、母集団全体をうまく反映できません。
そこで層化抽出法を使うと、各層をバランスよく含めやすくなります。
特徴
・母集団の構成を反映しやすい
・推定精度が上がることがある
・層ごとの比較もしやすい
注意点
・どの変数で層を作るかを事前に考える必要がある
・層情報が分かっていないと使いにくい
実務でも非常によく使われる考え方です。
3. 系統抽出法
系統抽出法は、母集団を並べたうえで、一定間隔ごとに標本を抽出する方法です。
たとえば、名簿順に並んだ1000人の中から、最初の1人をランダムに決めて、その後は10人ごとに1人ずつ選ぶ、といった方法です。
特徴
・実施しやすい
・抽出作業が効率的
・大規模データでも扱いやすい
注意点
・名簿の並び方に周期性があると偏りが生じることがある
たとえば、名簿の並びに規則性がある場合、その規則と抽出間隔が重なると標本が偏る可能性があります。そのため、見た目は簡単でも、並び順には注意が必要です。
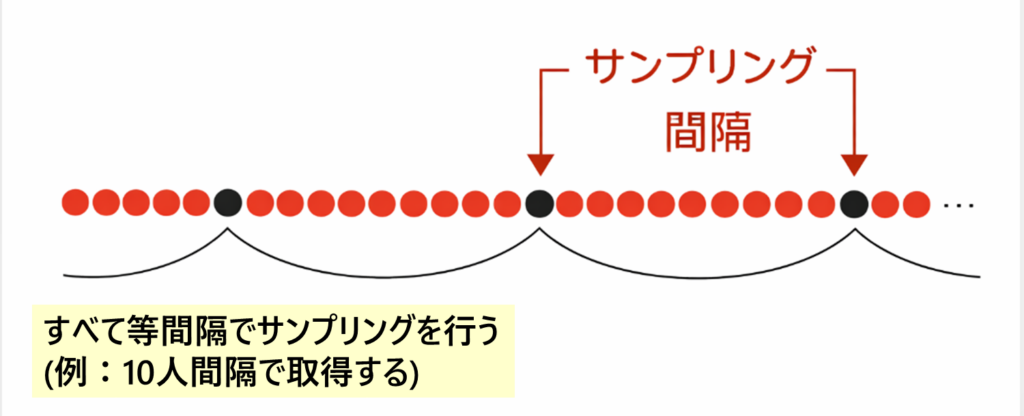
4. 集落抽出法
集落抽出法は、母集団をいくつかの集落(グループ)に分け、その集落単位で抽出する方法です。
たとえば、
・学校をいくつか選ぶ
・地区をいくつか選ぶ
・工場ラインをいくつか選ぶ
といったように、まずグループごと選び、その中全体を調査対象にします。
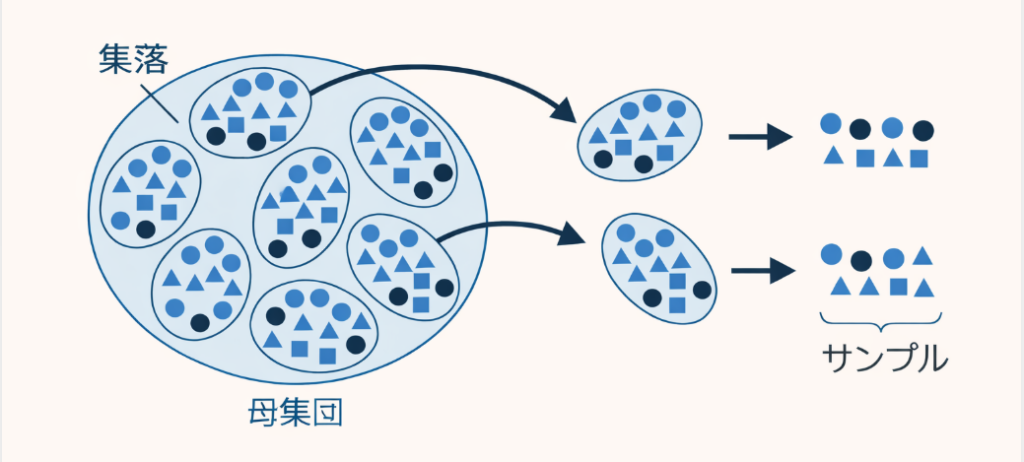
層化抽出法との違い
層化抽出法はすべての層から一部ずつ取る考え方です。
一方、集落抽出法はいくつかの集落そのものを選ぶ考え方です。
この2つは名前が似ていますが、考え方はかなり違います。
特徴
・調査コストを下げやすい
・地理的に広い母集団で有効
・実地調査に向いている
注意点
・集落ごとの差が大きいと、標本のばらつきが大きくなることがある
・単純無作為抽出より精度が下がることもある
実務では調査のしやすさから選ばれることがありますが、理論上は精度面の検討も必要です。
5. 多段抽出法
多段抽出法は、抽出を複数の段階に分けて行う方法です。
たとえば、
1.↓ 県を選ぶ
2.↓ その中から市町村を選ぶ
3.↓ その中から世帯を選ぶ
4.↓ その中から個人を選ぶ
というように、段階的に対象を絞っていきます。
特徴
・大規模調査に向いている
・現実的な調査設計をしやすい
・地域調査や社会調査でよく使われる
注意点
・抽出設計が複雑になる
・誤差の扱いも単純ではなくなる(要因が幾重にも伝播するため)
大規模な調査では非常に実用的ですが、理論的には単純な抽出より複雑になります。
6. 有意抽出法
有意抽出法は、調査者が意図をもって対象を選ぶ方法です。
設計者が意図的に対象を選ぶため、確率的に選択していたこれまでの抽出法とは大きく異なります。
たとえば、
・代表的だと思う人を選ぶ
・条件に合う事例を選ぶ
・調査しやすい対象を選ぶ
などがこれに当たります。
特徴
・実施しやすい
・探索的な調査では使われることがある
注意点
有意抽出方が簡単に実施できる分人による人為的な操作が入るため設計には注意が必要です。
・偏りが入りやすい
・母集団を代表している保証が弱い(なぜそうしたのか説明が必要)
・推測統計には向かないことが多い
統計検定では、無作為抽出ではないため注意が必要な方法として扱われることが多いです。
7. 便宜抽出法
便宜抽出法は、集めやすい対象をそのまま集める方法です。
たとえば、
・身近な人にだけアンケートする
・回答してくれた人だけを集計する
・その場にいた人だけを対象にする
といった方法が該当します。
特徴
・とても実施しやすい(実質的な制約はない)
・予備調査では使われることがある
注意点
・偏りが非常に入りやすい
・母集団の代表性が弱い
・結果を一般化しにくい
実務ではありがちな方法ですが、統計的な厳密さという意味では注意が必要です。
どの抽出法が良いのか?
ここで気になるのは、「結局どの抽出法が一番良いのか」という点かもしれません。
ただ、これは単純に一つに決められる話ではありません。
なぜなら、抽出法は「何を母集団と考えるか」「どの程度の精度が必要か?」「コストは?」といった複数の要因にによって適切な方法が変わるからです。
理論的には単純無作為抽出法が基本ですが、
現実には層化抽出法、集落抽出法、多段抽出法などを組み合わせて使うことも多いです。
重要なのは、分析の前に、母集団と抽出法を明確にすることです。
この辺りが、技術者としての腕の見せ所だと筆者は考えています(私も修行中です・・・)
なぜ「データの取り方」がそこまで重要なのか?
統計解析では、回帰分析や仮説検定などの手法に目が向きやすいですが、
そもそもデータの取り方が適切でなければ、その後の解析結果は不安定になります。
そうすると、
・偏った標本から平均を計算しても、母集団の平均をうまく表さない
・偏った標本から相関係数を求めても、母集団の関連性を正しく反映しない
・偏った標本で仮説検定をしても、結論の信頼性が低くなる
ということが起こります。
つまり、
統計解析の質は、解析手法だけでなく、データ取得の段階でかなり決まる
ということです。
これは統計の基礎でありながら、実務でも非常に重要な考え方です。
まとめ
データの取得方法は、統計解析の出発点です。
この記事のポイント
・まず母集団を明確にすることが重要
・標本調査では、抽出法によって結果の信頼性が変わる
・単純無作為抽出法は基本となる方法
・層化抽出法は母集団の構成を反映しやすい
・系統抽出法は効率的だが並び順に注意が必要
・集落抽出法と多段抽出法は大規模調査で実用的
・有意抽出法や便宜抽出法は偏りに注意が必要
・統計解析の前に、どんな母集団を仮定してデータを取るかが非常に重要
統計というと、計算や解析手法に注目が集まりやすいですが、
本当に信頼できる結論を得るためには、データの集め方そのものを丁寧に考える必要があります。
どの母集団について知りたいのか。その母集団を反映するように、どう標本を取るのか。
この視点を持つだけで、統計の理解はかなり深まります。
あわせて読みたい

統計解析の超基本概念「母集団と標本」についてわかりやすく解説!(最初に読みたい)